The Genetic Code Overview
This module will examine how information is encoded in DNA, and how that information is interpreted to bring about changes in cells and tissues.
Objectives :
Order custom essay The Genetic Code Overview with free plagiarism report
- Understand the triplet nature of the genetic code, and know the meaning of the term codon
- Know that the code is degenerate, and what that means
- Know that the code is unambiguous, and what that means
- Know the identities of the start and stop codons, and understand how they work
The Genetic Code It has been mentioned in a variety of modules that DNA stores genetic information.
That much was clear from the experiments of Avery, Macleod, and McCarty and Hershey and Chase. However, these experiments did not explain how DNA stores genetic information. Elucidation of the structure of DNA by Watson and Crick did not offer an obvious explanation of how the information might be stored. DNA was constructed from nucleotides containing only four possible bases (A, G, C, and T). The big question was: how do you code for all of the traits of an organism using only a four letter alphabet? Recall the central dogma of molecular biology.
The information stored in DNA is ultimately transferred to protein, which is what gives cells and tissues their particular properties. Proteins are linear chains of amino acids, and there are 20 amino acids found in proteins. So the real question becomes: how does a four letter alphabet code for all possible combinations of 20 amino acids? By constructing multi-letter "words" out of the four letters in the alphabet, it is possible to code for all of the amino acids. Specifically, it is possible to make 64 different three letter words from just the four letters of the genetic alphabet, which covers the 20 amino acids easily.
This kind of reasoning led to the proposal of a triplet genetic code. Experiments involving in vitro translation of short synthetic RNAs eventually confirmed that the genetic code is indeed a triplet code. The three-letter "words" of the genetic code are known as codons. This experimental approach was also used to work out the relationship between individual codons and the various amino acids. After this "cracking" of the genetic code, several properties of the genetic code became apparent: The genetic code is composed of nucleotide triplets.
In other words, three nucleotides in mRNA (a codon) specify one amino acid in a protein. The code is non-overlapping. This means that successive triplets are read in order. Each nucleotide is part of only one triplet codon. The genetic code is unambiguous. Each codon specifies a particular amino acid, and only one amino acid. In other words, the codon ACG codes for the amino acid threonine, and only threonine. The genetic code is degenerate. In contrast, each amino acid can be specified by more than one codon. The code is nearly universal.
Almost all organisms in nature (from bacteria to humans) use exactly the same genetic code. The rare exceptions include some changes in the code in mitochondria, and in a few protozoan species. A Non-overlapping Code. The genetic code is read in groups (or "words") of three nucleotides. After reading one triplet, the "reading frame" shifts over three letters, not just one or two. In the following example, the code would not be read GAC, ACU, CUG, UGA... Rather, the code would be read GAC, UGA, CUG, ACU... Degeneracy of the Genetic Code There are 64 different triplet codons, and only 20 amino acids. Unless some amino acids are specified by more than one codon, some codons would be completely meaningless. Therefore, some redundancy is built into the system: some amino acids are coded for by multiple codons. In some cases, the redundant codons are related to each other by sequence; for example, leucine is specified by the codons CUU, CUA, CUC, and CUG. Note how the codons are the same except for the third nucleotide position. This third position is known as the "wobble" position of the codon.
This is because in a number of cases, the identity of the base at the third position can wobble, and the same amino acid will still be specified. This property allows some protection against mutation - if a mutation occurs at the third position of a codon, there is a good chance that the amino acid specified in the encoded protein won't change. Reading Frames.If you think about it, because the genetic code is triplet based, there are three possible ways a particular message can be read, as shown in the following figure: Clearly, each of these would yield completely different results.
To illustrate the point using an analogy, consider the following set of letters: the red fox at e the hot dog . If this string of letters is read three letters at a time, there is one reading frame that works: the red fox ate the hot dog and two reading frames that produce nonsense: t her edf oxa tet heh otd og th ere dfo xat eth eho tdo g. Genetic messages work much the same way: there is one reading frame that makes sense, and two reading frames that are nonsense. So how is the reading frame chosen for a particular mRNA? The answer is found in the genetic code itself.
The code contains signals for starting and stopping translation of the code. The start codon is AUG. AUG also codes for the amino acid methionine, but the first AUG encountered signals for translation to begin. The start codon sets the reading frame: AUG is the first triplet, and subsequent triplets are read in the same reading frame. Translation continues until a stop codon is encountered. There are three stop codons: UAA, UAG, and UGA. To be recognized as a stop codon, the triplet must be in the same reading frame as the start codon. A reading frame between a start codon and an in-frame stop codon is called an open reading frame.
Let's see how a sequence would be translated by considering the following sequence. First, the code is read in a 5' to 3' direction. The first AUG read in that direction sets the reading frame, and subsequent codons are read in frame, until the stop codon, UAA, is encountered. Note that there are three nucleotides, UAG (indicated by asterisks) that would otherwise constitute a stop codon, except that the codon is out of frame and is not recognized as a stop. In this sequence, there are nucleotides at either end that are outside of the open reading frame.
Because they are outside of the open reading frame, these nucleotides are not used to code for amino acids. This is a common situation in mRNA molecules. The region at the 5' end that is not translated is called the 5' untranslated region, or 5' UTR. The region at the 3' end is called the 3' UTR. These sequences, even though they do not encode any polypeptide sequence, are not wasted: in eukaryotes these regions typically contain regulatory sequences that can affect when a message gets translated, where in a cell an mRNA is localized, and how long an mRNA lasts in a cell before it is destroyed.
A detailed examination of these sequences is beyond the scope of this course.

The Genetic Code: Summary of Key Points
The genetic code is a triplet code, with codons of three bases coding for specific amino acids. Each triplet codon specifies only one amino acid, but an individual amino acid may be specified by more than one codon. A start codon, AUG, sets the reading frame, and signals the start of translation of the genetic code. Translation continues in a non-overlapping fashion until a stop codon (UAA, UAG, or UGA) is encountered in frame. The nucleotides between the start and stop codons comprise an open reading frame.
Cite this Page
The Genetic Code Overview. (2017, Apr 02). Retrieved from https://phdessay.com/the-genetic-code/
Run a free check or have your essay done for you

More related essays
Genes are what code particular traits and characteristics and are the influence to health and disease. Ongoing advances are now making It available for parents to genetically modify Implanted embryos.
The term "genetic engineering" was first coined by Jack Williamson in is science fiction novel Dragon's Island, published in 1 951 ,one year before Dona's role in heredity was confirmed.
4 November 2013 Section 24 TA- Erik Ohlson Meiosis and Genetic Diversity in the Model Organism, Sordaria flmicola Introduction Research groups from the Imperial College of Science, Technology and Medicine.
Genetic Testing at Burlington Northern People wake up everyday, get ready for day, and start off to work. At work we never think about dying or getting hurt. So we.
Genetic Discrimination 1. Genetic discrimination is prejudice against those who have or are likely to develop an inherited disorder. This is where individuals are tested for certain mutations in their.
Genetic Counselors are professional who have completed a master’s program in medical genetics and counseling skills. They then pass a certification exam administered by the American Board of Genetics Counseling..
Gene profiling and genetic fingerprinting was unheard of in Forensic Science 20 years ago. DNA testing was initially introduced in the 1980s and the first court case, which saw a.
Abstract Human genetic engineering is the manipulation of an individual's genotype with the goal of choosing the phenotype (Singers 1). This has already been a very controversial issue when it.
We use cookies to give you the best experience possible. By continuing we’ll assume you’re on board with our cookie policy
Save time and let our verified experts help you.
Home — Essay Samples — Science — Evolution — The Universal Genetic Code of Living Organisms
The Universal Genetic Code of Living Organisms
- Categories: Art History Cultural Anthropology Evolution
About this sample

Words: 489 |
Published: Mar 16, 2024
Words: 489 | Page: 1 | 3 min read

Cite this Essay
To export a reference to this article please select a referencing style below:
Let us write you an essay from scratch
- 450+ experts on 30 subjects ready to help
- Custom essay delivered in as few as 3 hours
Get high-quality help

Verified writer
- Expert in: Arts & Culture Science
+ 120 experts online
By clicking “Check Writers’ Offers”, you agree to our terms of service and privacy policy . We’ll occasionally send you promo and account related email
No need to pay just yet!
Related Essays
5 pages / 2183 words
2 pages / 952 words
2 pages / 696 words
2 pages / 893 words
Remember! This is just a sample.
You can get your custom paper by one of our expert writers.
121 writers online
Still can’t find what you need?
Browse our vast selection of original essay samples, each expertly formatted and styled
Related Essays on Evolution
In the vast arena of scientific inquiry, two theories have long been at odds: creationism and evolution. Creationism, rooted in religious beliefs and the narrative of a divine creator fashioning the world in a matter of days, [...]
When we think about the outcome of a mating, it’s often easy to get lost in the complexities of genetics, traits, and environmental factors. However, one particularly fascinating aspect is the potential for offspring to possess [...]
The debate between creationism and evolution has been a long-standing and contentious issue in the realm of science and religion. While creationism is rooted in religious beliefs and posits that the universe and all living [...]
When we think about the intricate relationships between humans and animals, it's easy to get lost in the myriad of ways we interact. From our furry companions at home to the majestic wildlife that roam the earth, these dynamics [...]
In conclusion, Leslie Norriss Blackberries are more than just a delicious fruit. They represent a journey into the world of botanical beauty, where history, cultivation, taste, and health intertwine. From their humble origins to [...]
The concept of "survival of the fittest" is intrinsically tied to the theory of evolution through natural selection, a groundbreaking idea put forth by Charles Darwin in 1858. This theory sought to explain how adaptation and [...]
Related Topics
By clicking “Send”, you agree to our Terms of service and Privacy statement . We will occasionally send you account related emails.
Where do you want us to send this sample?
By clicking “Continue”, you agree to our terms of service and privacy policy.
Be careful. This essay is not unique
This essay was donated by a student and is likely to have been used and submitted before
Download this Sample
Free samples may contain mistakes and not unique parts
Sorry, we could not paraphrase this essay. Our professional writers can rewrite it and get you a unique paper.
Please check your inbox.
We can write you a custom essay that will follow your exact instructions and meet the deadlines. Let's fix your grades together!
Get Your Personalized Essay in 3 Hours or Less!
We use cookies to personalyze your web-site experience. By continuing we’ll assume you board with our cookie policy .
- Instructions Followed To The Letter
- Deadlines Met At Every Stage
- Unique And Plagiarism Free

Genetic Code Essay
The genetic code consists of four nitrogenous bases that form two base pairs. These four nitrogenous bases store all the vital information necessary to generate life. The investigators in the experiment aimed to build upon the existing genetic code. The investigators synthesized unnatural base pairs (UBPs) to incorporate into the DNA of E. coli. cells. The UBPs were optimized in semisynthesized organisms (SSOs) to increase genomic storage. The investigators used multiple E. coli strains, plasmids, and synthesized oligonucleotides to conduct the experiment. Figure 1b displays different strains of E. coli. The test displayed by Figure 1b was useful because a suitable strain of E coli cells was identified. The YZ3 strain retained the UBPs necessary for …show more content…
Past tests used DM1, which was not as effective as YZ3 at UBP uptake or retention. Figure 5 is crowded and it is difficult to differentiate between the separate data. Some lines run together and overlap one another. The investigators could have plotted the lines on separate graphs to clarify the experimental data. The induction of Cas9 by IPTG is an important aspect of the experiment, therefore, the plot should have been more precise. Also, many of the growth curve figures have crowded data. The color coordinated lines make the data easier to distinguish, but the results could have been clearer. Ethically, the topic of the paper is controversial. Although, there are beneficial aspects of genetic engineering and modification of organisms. The ability to synthesize UBPs to create SSOs with new genomes, capable of increased capacity for genetic information, is astounding. Clustered regularly interspaced short palindromic repeats (CRISPR) can be used to completely inactivate genes with Cas9. CRISPR can also be used to insert synthesized sequences into DNA to alter a gene . CRISPR was used by the investigators in the paper to yield SSOs with a six-lettered genome. The experiment demonstrated that (using methods
I Am Kaylyn Stewart From The University Tech University
For many years biomedical researchers like myself have been trying to create more proactive ways to amend the genome for living cells. In more recent fieldwork studies there has been a new state of the art instrument based on bacterial CRISP in close works with protein 9 often referred to as CAS9 from the streptococcus progenies have possibly unlocked new data. The CRISP/CAS9 tries to manipulate the function of the gene using homologous recombination and RNA interference, but is set back because it can only provide short term restriction of the genes function and it’s iffy off- target effects.
Genetic Engineering DBQ Essay
Have you ever wondered what it would be like if everyone was smart, athletic, and beautiful? Well, recently, scientists have been experimenting with human DNA to make a “better” person. Mostly all of these embryos died off, and those who lived were the same as your average human (OI) . I do not believe it is morally right to use human DNA and genes to alter the appearance and abilities of people. Although people may argue otherwise, I know that this is not right.
Have you ever wondered what determines what you look like? This job is carried by a gene, which lies in long strands of DNA called chromosomes (OI). Genes can be modified to be “better”, and change what an organism will look like or have/not have certain conditions (OI). This is called genetic engineering, or genetically modifying an organism. I believe that human embryos should not be genetically modified because it can change the wrong genes, being too expensive, and changing how God wants us to live.
Manipulation And Analysis Of Dna Using Standard Molecular Biology Essay
Isolation of plasmid DNA from three cultures of E.coli using a method known as the alkaline lysis method.
Crispr Essay
though inserting genes into other animals, and even through the process of repairing damaged genes in a particular way, through the fibroblasts instigations. Overall Ruppy the beagle was important in leading to the development of CRISPR, and is one of the most important transgenic organisms in it’s history.
Cracking The Genetic Code Summary
The episode, Cracking the Genetic Code from the television series NOVA investigates the implications of being able to sequence an individual’s genetic code. Doctors and researcher explore personalized, gene based medicine. It discusses how knowledge of gene sequencing can be used to help patients suffering from serious diseases, such as Parkinson’s disease, and discusses how gene sequencing technology causes serious ethical concerns about privacy and discrimination.
Genetics Case Study Essay
Case Study One A 13-year-old named Marta displays exceeding aptitudes in athletics. Good genetics is the rationale used by her coach to explain why she is so advanced. Genetics can explain certain abilities, however there are other factors that impact on abilities. O’Donnell et al. (2016) supported the ideas that individual’s growth and development have consequently been impacted by genetics and environmental factors.
Universal Genetic Code Research Paper
All living organisms have a shared ancestor deep in the past, so all living organisms are related and share RNA to some degree. A universal genetic code relates To The hypothesis of the origin of life on earth because even though organisms can be completely different physically, they must all come from the same origin to share a similar genetic code. So that would mean all organisms originated from a single ancestor. self-replicating molecules explain how an organism could have a similar code to another organism. For example, a rabbit and a gray whale. Even though they are two completely different animals, they could have a similar genetic code. This wouldn’t be possible without self-replicating molecules that was passed down from ancestors.
' Let's Hit Pause Before Altering Humankind?
With modern technology comes the breakthrough of the decade by altering the human genes. This altering gene invention is called CRISPR/Cas9. However, this invention in the beginning stages of altering genes, began with rats until perfection. The process began early with the embryo stages to edit the genes. With the introduction of CRISPR surrounds a lot of controversy. Some people believe editing genes is playing with the hands of God and refuse to believe in CRISPR. With the article, “Let’s Hit Pause Before Altering Humankind”, by David Baltimore believes CRISPR is a tool with no good intentions. With this information the article should not be published with being against CRISPR.
The Human Genome Project Essay examples
- 10 Works Cited
The Human Genome Project (HGP), an international scientific research project, has educated the public tremendously on various topics concerning DNA and genetics. This study has been beneficial to communities alike. As stated, the HGP sought to identify all the genes in human DNA, determine the sequences of the three billion chemical base pairs that make up human DNA, store this information in databases, improve tools for data analysis, transfer related technologies to the private sector, and address the ethical, legal, and social issues that may arise from the project. In favor of achieving these goals, scientists studied the genetic makeup of several nonhuman organisms (Human Genome Management Information System, 2011).
Human Genetic Engineering Essay
- 3 Works Cited
What if you could design your child before it was even born? What if you could cut out any life threatening diseases, make sure that your child is not susceptible to smoking addictions or alcoholism, and then make your child genius? Would you? Are you asking yourself how this could be done? Have you ever considered human genetic engineering?
- 2 Works Cited
material of some viruses. RNA molecules are like DNA. They have a long chain of
DNA Essay example
DNA is a term that has been used in science as well as in many parts of daily
CRISPR-Cas9 Essay
During January of 2013, scientists based at the Broad Institute of MIT and Harvard were able to demonstrate fixed change in human and animal cells using CRISPR-Cas9. This marked a turning point in genetic advancement—though CRISPR was far from mastered, its potential was beginning to show.
Genome Editing Essay
Genome editing is a huge leap forward in science and medicine. Because of recent advances in technology, the study of genes and induced ‘point’ mutations have led to the discovery and advancement of methods previously used in order to mutate genes. The development of Clusters of Regularly Interspaced Short Palindromic Repeats (CRISPRs) and CRISPR associated system 9 protein (Cas9) technology is a hugely significant leap forward as this is a tool that could potentially be used for the research into and hopefully the treatment of a range of medical conditions that are genetically related. Cystic fibrosis (Schwank, G. et al, 2013), haemophilia and sickle cell disease are an example of some of the conditions that have the
Related Topics
- Molecular biology
- Escherichia coli
- Free Essays
- Citation Generator

The Genetic Code
You May Also Find These Documents Helpful
Btec level 3 unit 25 d2.
Deoxyribose Nucleic Acid (DNA) is a polynucleotide molecule that encodes the genetic instructions used in the development and functioning of all known living organisms and many viruses. Most DNA molecules are double stranded helices, consisting of two polynucleotide strands made up of simpler molecules known as nucleotides. A nucleotide is made up of an organic nitrogenous base, a deoxyribose sugar and phosphate groups. It is order of these bases which make up the genetic code; a set of rules, by which information is encoded within genetic material.…
Dna Sci/230
3. Describe each stage of the flow of information starting with DNA and ending with a trait.…
Wgu Biochemistry Task 1
Santi, L., Maggioli, C., Mastroroberto, M., Tufoni, M., Napoli, l., & Caraceni, P. (2012). Acute liver failure caused by…
dna worksheet
U3ip graphic organizer.
Explanation: The first codon of an mRNA transcript is called initiation codon and it initiates the translation process, which is necessary for formation of a protein. The last codon is known as a Stop codon as it stops the translation process to end the addition of amino acids to protein chain. In absence of Stop codon the protein formation is never completed as there would uninhibited addition of amino acids.…
Dna Worksheet
The flow of information from gene to protein is based on the triplet code. The genetic instructions for the amino acid sequence of a polypeptide chain are written in DNA and RNA as a series of three-base words called codons. The three-base codons in DNA are transcribed into complementary three-base codons in RNA, and then the RNA codons are translated into amino…
Biology 1010 Study Notes
16. How do the DNA base sequences specify the sequences of amino acids in a protein?…
Revision Questions
1. A portion of specific DNA molecule consists of the following sequence of nucleotide triplets.…
D Arcy V Myriad Genetics Inc Case Study
The sequences of DNA that comprise a gene are referred to as exons or exonic sequences. Most exonic sequences will code for a particular protein, but they also include other regulatory or non-coding regions that, although not coding for a particular protein, are important to the translation of mRNA. These non-coding sequences are referred to as untranslated regions (UTR) and occur at the 5’ end (5’ UTR) and 3’ end (3’ UTR) of the gene. Other sequences that do not code for protein, and which do not form part of the UTR of the gene, are referred to as introns or intronic sequences. Introns are found in DNA and pre-mRNA, but not in mRNA, which includes only the exonic sequences found in the DNA from which it is copied. Introns account for about 25% of the human genome. The remainder is made up of repetitive and other intergenic…
Reversing Entries
Dna work sheet.
. This flow of information is dependent on the genetic code, which defines the relation between the sequence of bases in DNA (or its mRNA…
Biology Questions
Apply: Suppose you wanted a protein that consists of the amino acid sequence methionine, asparagine, valine, and histidine. Give an mRNA sequence that would code for this protein.…
Ways in which living organisms differ from each other
DNA consists of two polynucleotide chains and these nucleotides consist of a deoxyribose sugar, a nitrogenous base and a phosphate group. The bases are Adenine, Cytosine, Guanine and Thymine. The sequence of these bases on DNA determines the structure of these proteins. A gene is a sequence of bases which codes for a single polypeptide. Chromosomes carry these genes and these genes come in specific forms called an allele which is how living organisms vary from each other. For example, humans are made up of an XY or XX chromosome. Females are XX and males are XY, however in some animals their sex is determined by the ZW sex-determination…
Related Topics

Understanding the Genetic Code – Exploring the Blueprint of Life with Real-Life Examples
- Post author By admin-science
- Post date 20.12.2023
The genetic code is a fundamental concept in biology that helps explain how the information contained in DNA is used to create proteins. DNA, or deoxyribonucleic acid, is composed of a sequence of nucleotides that act as the blueprint for life. Each nucleotide contains a sugar, a phosphate group, and one of four nitrogenous bases: adenine (A), guanine (G), cytosine (C), or thymine (T).
Proteins, on the other hand, are made up of chains of amino acids. There are 20 different amino acids that can be combined in various sequences to create the vast array of proteins found in living organisms. The genetic code is the set of rules that determines how the sequence of nucleotides in DNA is translated into the sequence of amino acids in a protein.
The genetic code is composed of codons, which are sequences of three nucleotides. Each codon corresponds to a specific amino acid or a stop signal. For example, the codon “AUG” codes for the amino acid methionine, which is often the start signal for protein synthesis. There are also codons that act as stop signals, such as “UAA”, “UAG”, and “UGA”, which indicate the end of the protein sequence.
Understanding the genetic code is crucial for understanding how mutations can lead to changes in protein structure and function. Mutations are alterations in the sequence of nucleotides in DNA, and they can occur spontaneously or as a result of environmental factors. A single nucleotide change can lead to a different amino acid being incorporated into a protein, which can have profound effects on its structure and function.
The Basics of Genetics
Genetics is the study of how traits and characteristics are passed down from one generation to the next. It focuses on the role of genes, which are segments of DNA that contain the instructions for building and maintaining an organism.
One of the key concepts in genetics is mutation. Mutations are changes in the genetic code that can occur spontaneously or as a result of environmental factors. These changes can alter the sequence of nucleotides in DNA, which can in turn change the sequence of amino acids in a protein.
The genetic code is the set of rules by which information encoded within a DNA sequence is translated into the amino acid sequence of a protein. Each three-nucleotide sequence, known as a codon, corresponds to a specific amino acid or a start/stop signal. For example, the codon “AUG” codes for the amino acid methionine, and the codon “UGA” is a stop signal that indicates the end of a protein.
To understand the basics of genetics, let’s consider an example. Imagine a DNA sequence with the following set of codons: “ACG”, “GGA”, “CAA”, “CCT”. This sequence would be translated into the amino acid sequence: threonine, glycine, glutamine, proline. These amino acids would then come together to form a protein with a specific function in the organism.
Genetics plays a vital role in understanding inheritance patterns, genetic disorders, and the development of new therapies. By studying the genetic code and how it is expressed, scientists can gain insights into the fundamental processes that govern life.
The Structure of DNA
DNA, also known as deoxyribonucleic acid, is a long molecule that carries the genetic code of an organism. It consists of two strands that are twisted together in a double helix structure. Each strand is made up of nucleotides, which are the building blocks of DNA.
Each nucleotide consists of a sugar molecule (deoxyribose), a phosphate group, and a nitrogenous base. There are four types of nitrogenous bases: adenine (A), thymine (T), cytosine (C), and guanine (G). These bases pair up with each other to form the rungs of the DNA ladder. A always pairs with T, and C always pairs with G.
The sequence of these nucleotides along the DNA molecule determines the genetic code. For example, the sequence CTAGC would code for a specific protein. The genetic code is read in groups of three nucleotides, called codons. Each codon corresponds to a specific amino acid, which is the building block of proteins.
Mutations, or changes in the DNA sequence, can have a significant impact on an organism. They can alter the genetic code, leading to changes in protein structure and function. Some mutations may be harmful, while others may be beneficial or have no effect.
The structure of DNA and the genetic code it carries are essential for understanding how genetic information is stored and passed on from generation to generation. By studying DNA, scientists can unravel the mysteries of life and gain insights into diseases, evolution, and other biological processes.
The Genetic Code
The genetic code is a set of rules that determines how the sequence of nucleotides in a section of DNA is translated into the sequence of amino acids in a protein. Each set of three nucleotides, called a codon, codes for a specific amino acid. For example, the codon “AUG” codes for the amino acid methionine.
The genetic code is universal, meaning it is the same in all organisms. This allows scientists to compare DNA sequences from different species and determine how closely related they are. It also allows for the transfer of genetic information between organisms.
Mutations in the genetic code can lead to changes in the amino acid sequence of a protein. This can have significant effects on an organism’s biology. For example, a single mutation in the genetic code can lead to the production of a non-functional protein, which can result in diseases like cystic fibrosis or sickle cell anemia.
To understand the genetic code, scientists created a table called the codon table. This table lists all possible codons and the corresponding amino acid they code for. By using this table, scientists can determine the amino acid sequence of a protein based on its DNA sequence.
By understanding the genetic code, scientists can better understand how traits are passed down from generation to generation and how mutations can lead to genetic disorders. This knowledge is essential for advancements in medicine and genetic engineering.
Encoding and Decoding
The genetic code is the set of rules that determines how the genetic information stored in DNA is decoded and translated into proteins. It is a universal code that is shared by all living organisms.
The process of encoding and decoding the genetic information involves several steps. First, the DNA sequence is transcribed into a messenger RNA (mRNA) molecule. This process, called transcription, occurs in the nucleus of the cell. The mRNA molecule carries the genetic information from the DNA to the ribosomes, where proteins are synthesized.
The genetic code is a triplet code, meaning that each three nucleotides in the DNA sequence, known as a codon, codes for a specific amino acid or a stop signal. There are 64 possible codons, but only 20 different amino acids. This means that most amino acids are encoded by more than one codon. For example, the codons GCU, GCC, GCA, and GCG all code for the amino acid alanine.
During translation, the mRNA sequence is read by the ribosome in sets of three nucleotides, and the corresponding amino acid is added to the growing protein chain. This process continues until a stop codon is encountered, signaling the end of protein synthesis.
Understanding the genetic code is important in studying genetic diseases and mutations. Mutations can occur when there is a change in the DNA sequence. These changes in the genetic code can lead to alterations in the amino acid sequence and affect the structure and function of the resulting protein. For example, a mutation that changes a codon for a specific amino acid to a different codon can result in a different amino acid being incorporated into the protein chain, leading to a functional change or loss of function.
Let’s take an example to illustrate the encoding and decoding process. Consider the DNA sequence: ATGCGTACG. This DNA sequence is transcribed into mRNA as AUGCGUACG. During translation, the ribosome reads the mRNA sequence in codons: AUG, CGU, ACG. Each codon codes for a specific amino acid or a stop signal. In this case, the codons AUG and ACG code for the amino acids methionine and threonine, respectively. The resulting protein chain would start with methionine (Met) and end with threonine (Thr).
This example demonstrates how the genetic code is used to encode the DNA sequence into mRNA and decode it into a protein sequence. The genetic code provides the blueprint for building proteins, which play vital roles in cellular processes and the functioning of living organisms.
DNA Replication
DNA replication is the process by which a double-stranded DNA molecule is copied to produce two identical DNA molecules. This process is crucial for cell division and the inheritance of genetic information.
DNA replication begins with the unwinding of the double helix structure of the DNA molecule. This is done by enzymes called helicases, which separate the two strands of the DNA. Once the DNA strands are separated, other enzymes called DNA polymerases begin to synthesize new strands of DNA using the existing strands as templates.
During DNA replication, each nucleotide in the DNA molecule is paired with its complementary nucleotide. Adenine (A) always pairs with thymine (T), and cytosine (C) always pairs with guanine (G). This is known as the base-pairing rule and is crucial for the accurate copying of the DNA sequence.
DNA replication is a highly accurate process, but occasionally mistakes, or mutations, can occur. Mutations are changes in the DNA sequence and can lead to changes in the genetic code, which can have various effects on the protein that is encoded by the DNA.
An example of a mutation in the genetic code is a substitution mutation. This occurs when one nucleotide is replaced with a different nucleotide. For example, if the original DNA sequence is “ATG”, a substitution mutation can change it to “ACG” if the thymine (T) is replaced with a cytosine (C). This mutation can result in a change in the amino acid sequence of the resulting protein.
In summary, DNA replication is the process by which a double-stranded DNA molecule is copied to produce two identical DNA molecules. This process is essential for the accurate transmission of genetic information and can occasionally result in mutations that can lead to changes in the protein produced.
Transcription
Transcription is a fundamental process in molecular biology where a single-stranded DNA sequence is used as a template to create a complementary RNA molecule. This is an essential step in gene expression, as it allows the genetic code to be translated into a functional protein.
During transcription, an enzyme called RNA polymerase binds to a specific region of the DNA molecule called the promoter region. The RNA polymerase helps to unwind the DNA double helix, exposing the nucleotide bases on one of the DNA strands. As the RNA polymerase moves along the DNA strand, it adds complementary RNA nucleotides to the growing RNA molecule, based on the sequence of the DNA template strand.
The genetic code is read in groups of three nucleotides, known as codons. Each codon corresponds to a specific amino acid, which is the building block of proteins. For example, the codon “AUG” corresponds to the amino acid methionine.
Once the RNA molecule is complete, it detaches from the DNA template and undergoes further processing to become a mature mRNA molecule. This mature mRNA molecule can then be transported out of the nucleus and into the cytoplasm of the cell, where it will be used as a template for protein synthesis.
Translation
In genetics, translation is the process where the genetic information encoded in DNA is converted into amino acid sequences, which ultimately form proteins . This process is crucial for the functioning of living organisms as it determines the structure and function of proteins.
The genetic code is a set of rules that relates each nucleotide triplet, called a codon, to a specific amino acid. This code is generally universal across all known organisms.
To understand translation , let’s consider an example. Suppose we have a DNA sequence that contains the following codons: ATG, GGA, CTC, and TAA.
Step 1: The process of translation begins when the DNA sequence is transcribed into an messenger RNA (mRNA) molecule. This molecule carries the genetic information from the DNA to the ribosomes, where translation takes place.
Step 2: The mRNA molecule is then read by specialized molecules called ribosomes . The ribosomes move along the mRNA, matching each codon with the corresponding tRNA molecule carrying the corresponding amino acid.
Step 3: As the ribosome moves along the mRNA, it adds the amino acids that correspond to each codon, forming a polypeptide chain . This chain will eventually fold into a functional protein.
In our example, the codon “ATG” codes for the amino acid methionine. The codon “GGA” codes for glycine, “CTC” codes for leucine, and “TAA” is a stop codon, indicating the end of translation.
Overall, translation is a highly regulated and intricate process that plays a crucial role in determining the structure and function of proteins, which are essential for the functioning of living organisms.
Gene Expression
Gene expression is the process by which the genetic code stored in a gene is used to direct the synthesis of a functional protein. The genetic code is a sequence of nucleotides, and the specific sequence determines the sequence of amino acids in a protein. Gene expression plays a critical role in determining the structure and function of an organism.
For example, let’s consider a gene that codes for a specific protein. The DNA sequence of the gene is transcribed into a messenger RNA (mRNA) molecule, which is then translated into a sequence of amino acids, forming a protein. This process involves several steps, including transcription and translation.
A mutation in the DNA sequence can result in changes to the genetic code. For example, a mutation that changes a single nucleotide can result in a different amino acid being incorporated into the protein, potentially altering its structure and function.
The genetic code is read in sets of three nucleotides called codons. Each codon codes for a specific amino acid, except for a few codons that act as start or stop signals. For example, the codon AUG codes for the amino acid methionine and also serves as the start codon for protein synthesis.
The sequence of codons in a gene determines the sequence of amino acids in the resulting protein. This sequence ultimately determines the structure and function of the protein. Different genes have different sequences of codons, resulting in the production of different proteins with different functions.
In summary, gene expression is the process by which the genetic code is used to synthesize proteins. Mutations in the genetic code can lead to changes in protein structure and function. The sequence of codons in a gene determines the sequence of amino acids in the resulting protein, which in turn determines its structure and function.
Role of RNA
RNA plays a crucial role in the genetic code, acting as a messenger between DNA and proteins. It is essential in the process of protein synthesis, where the instructions encoded in DNA are translated into the production of specific proteins.
One example of the role RNA plays is in the formation of amino acids. Using the genetic information stored in DNA, RNA molecules are transcribed from the DNA template. These RNA molecules, known as messenger RNA (mRNA), carry the genetic code from the nucleus to the ribosomes, where proteins are synthesized.
During the process of translation, the ribosomes read the mRNA sequence, which consists of a series of nucleotides. Each nucleotide in the mRNA sequence represents a specific amino acid. The sequence of nucleotides determines the specific order in which amino acids are joined together to form a protein.
Transfer RNA (tRNA)
Another type of RNA, called transfer RNA (tRNA), plays a key role in protein synthesis. tRNA molecules bind to specific amino acids and carry them to the ribosomes. Each tRNA molecule has a specific sequence of nucleotides, called the anticodon, that matches a particular codon on the mRNA. This matching ensures that the correct amino acid is added to the growing protein chain.
Role in Mutation
RNA is also involved in the process of mutation, which is a change in the genetic code. Mutations can occur due to errors in DNA replication or as a result of exposure to mutagenic agents. RNA molecules, particularly RNA polymerase, are responsible for copying the DNA sequence during replication. Any errors or mutations in the RNA molecule can lead to changes in the resulting protein, potentially affecting its structure and function.
In conclusion, RNA plays a vital role in the genetic code by acting as a messenger between DNA and proteins. It is involved in the synthesis of proteins through its role in transcription, translation, and the transportation of amino acids. Additionally, RNA is also involved in the process of mutation, which can lead to changes in protein structure and function.
Codon and Anticodon
In the genetic code, DNA sequences are transcribed into RNA sequences, which are then translated into proteins. The genetic code consists of a sequence of nucleotides, with each nucleotide representing a specific base: adenine (A), cytosine (C), guanine (G), or thymine (T) in DNA, and adenine (A), cytosine (C), guanine (G), or uracil (U) in RNA. These nucleotides are grouped into codons, which are three-base sequences that code for a specific amino acid.
The codons are read by molecules called transfer RNA (tRNA), which have a complementary sequence called the anticodon. The anticodon is like a mirror image of the codon, allowing the tRNA to bind to the codon in the mRNA during protein synthesis. Each tRNA molecule is specialized to carry a specific amino acid, and when the tRNA binds to the codon, the amino acid is added to the growing protein chain.
Codon Usage and Mutations
The genetic code is degenerate, meaning that some amino acids can be coded by multiple codons. For example, the amino acid phenylalanine can be coded by the codons UUU or UUC. This redundancy in the genetic code provides some protection against mutations, as a single base substitution may not always result in a change in the amino acid sequence. However, some codons are used more frequently than others, a phenomenon known as codon usage bias.
Mutations can occur in the DNA sequence, leading to changes in the codons and potentially affecting the protein sequence. Point mutations, such as single base substitutions, can result in the substitution of one amino acid for another, potentially altering the structure and function of the protein. Insertions or deletions of nucleotides can also lead to frame-shift mutations, where the codon reading frame is shifted, and the entire sequence of codons is changed.
Protein Synthesis and the Genetic Code
The genetic code is crucial for protein synthesis, as it provides the instructions for the correct sequencing of amino acids in a protein. The sequence of codons in mRNA determines the sequence of amino acids that will be added to the protein chain. Once the correct codons have been read by the tRNA molecules, the amino acids are linked together, forming peptide bonds and creating the primary structure of the protein. The protein then folds into its three-dimensional structure, which determines its function in the cell.
Understanding the codon and anticodon relationship is essential for comprehending the intricacies of the genetic code. This knowledge helps scientists decipher the DNA sequence and predict the amino acid sequence and structure of proteins, aiding in various fields such as medicine, biotechnology, and evolutionary biology.
Start and Stop Codons
In the DNA genetic code, sequences of nucleotides determine the order in which amino acids are assembled to form proteins. These sequences are made up of three-letter segments called codons.
Start codons are special codons that initiate the process of protein synthesis. The most common start codon is AUG, which codes for the amino acid methionine. This codon tells the cellular machinery to begin reading the DNA sequence and start building the protein.
Stop codons, on the other hand, indicate the end of protein synthesis. There are three stop codons: UAA, UAG, and UGA. These codons do not code for any amino acid; instead, they signal the ribosomes to stop adding amino acids to the growing protein chain and complete the synthesis.
It is important to note that mutations in the start or stop codons can have significant effects on protein synthesis. For example, if a mutation occurs in the start codon, the ribosomes may not be able to recognize it and protein synthesis may be disrupted. Similarly, mutations in the stop codons can lead to the production of abnormally long proteins.
Understanding the genetic code and the role of start and stop codons is crucial in studying and deciphering the complex processes involved in protein synthesis.
DNA is made up of a sequence of nucleotides, and this sequence forms the genetic code. Mutations are changes in this genetic code that can have a variety of effects.
There are different types of mutations, including:
- Point mutations: these involve a change in a single nucleotide in the DNA sequence. For example, a substitution mutation may occur when one nucleotide is replaced by another.
- Insertion mutations: these involve the addition of one or more nucleotides to the DNA sequence. This can shift the reading frame of the genetic code and lead to changes in the resulting protein.
- Deletion mutations: these involve the removal of one or more nucleotides from the DNA sequence. Like insertion mutations, this can also cause a shift in the reading frame and alter the protein sequence.
The effects of mutations can vary. Sometimes, mutations have no effect on the resulting protein or organism. Other times, mutations can lead to changes in protein structure or function, which can impact an organism’s traits or health.
For example, a point mutation in the genetic code may result in a different amino acid being incorporated into a protein, which can alter its shape and function. In some cases, mutations can even lead to the production of an entirely new protein.
Overall, mutations are an important source of genetic variation and can play a role in evolution and the diversity of life on Earth.
Types of Mutations
Mutations are changes in the genetic sequence of an organism’s DNA. They can occur in different ways and have different effects on the resulting protein. Here are some examples of different types of mutations:
Point Mutations
Point mutations occur when a single nucleotide is changed, inserted, or deleted in the DNA sequence. This can lead to a change in the corresponding amino acid in the protein, resulting in a different protein structure and function. For example, a point mutation in the DNA sequence for hemoglobin can cause sickle cell disease.
Insertions and Deletions
Insertions and deletions, also known as indels, occur when one or more nucleotides are inserted or deleted from the DNA sequence. This can cause a shift in the reading frame, leading to a completely different amino acid sequence and protein. For example, an insertion or deletion in the DNA sequence could result in the production of a non-functional protein.
Mutations can have different effects on the resulting protein, ranging from no effect to a complete loss of function. It is important to note that mutations are not always negative; they can also lead to beneficial changes in an organism’s genetic makeup, providing advantages in certain environments. However, harmful mutations can cause genetic disorders and diseases.
Understanding the different types of mutations is crucial for studying and researching genetic disorders and diseases. By studying the effects of mutations, scientists can gain insights into the functions of genes and proteins, as well as develop treatments and therapies for genetic conditions.
Effects of Mutations
Mutations are changes in the genetic code, specifically in the sequence of nucleotides within DNA. These changes can have various effects on the functioning of genes, ultimately affecting the production of proteins.
Substitution Mutations
Substitution mutations occur when a single nucleotide is replaced by another nucleotide in the DNA sequence. For example, if the nucleotide adenine (A) is replaced by cytosine (C), it can result in a different amino acid being added to the growing protein chain during translation. This change in the amino acid sequence can potentially alter the structure and function of the protein.
Insertion and Deletion Mutations
Insertion and deletion mutations involve the addition or removal of one or more nucleotides from the DNA sequence. These mutations can lead to a shift in the reading frame, where the codons are read in a different way, resulting in a different sequence of amino acids. This can drastically change the structure and function of the protein.
For example, if a nucleotide is inserted or deleted within a coding region, it can disrupt the reading frame, causing the subsequent codons to be read incorrectly. This can lead to a completely different amino acid sequence and potentially non-functional protein.
Overall, mutations can have significant effects on the genetic code, altering the sequence of amino acids in proteins and potentially leading to changes in protein structure and function.
Examples of Mutations
Mutations are changes in the genetic code, specifically in the DNA sequence. These changes can affect the function of proteins and the production of amino acids, leading to various outcomes in organisms.
Point Mutation
A point mutation is a genetic mutation that occurs when a single nucleotide is changed, inserted, or deleted. This type of mutation can have different effects on the resulting mRNA and protein.
Frameshift Mutation
Frameshift mutations occur when nucleotides are inserted or deleted in the DNA sequence, causing a shift in the reading frame of the mRNA. This can result in a completely different protein being produced.
These examples illustrate the different types of mutations that can occur in the genetic code and the potential impact on protein production and function.
Genetic Disorders
Genetic disorders are diseases or conditions that arise due to a mutation or change in a person’s DNA sequence. These mutations can occur in various genes, affecting the production of specific proteins. The DNA code, made up of nucleotides, provides instructions for the assembly of amino acids into proteins.
When a mutation occurs in the genetic code, it can lead to the production of a defective protein or the absence of a necessary protein. This disruption in protein function can result in a wide range of genetic disorders.
For example, cystic fibrosis is a genetic disorder caused by a mutation in the CFTR gene. This mutation leads to the production of a faulty protein that affects the transport of chloride ions across cell membranes. As a result, mucus becomes thick and sticky, causing blockages in various organs such as the lungs and digestive system.
Another example is sickle cell anemia, which is caused by a mutation in the HBB gene. This mutation results in the production of abnormal hemoglobin, a protein responsible for carrying oxygen in red blood cells. The abnormal hemoglobin causes the red blood cells to become misshapen, leading to a range of symptoms including fatigue, pain, and organ damage.
Genetic disorders can be inherited from one or both parents, or they can occur spontaneously due to random mutations. Some genetic disorders are more common in certain populations, while others can be rare.
Understanding the genetic basis of these disorders is important for diagnosis, treatment, and genetic counseling. Researchers continue to study the genetic code and its implications in order to develop new therapies and interventions for individuals with genetic disorders.
Genetic Code Variations
The genetic code is the sequence of nucleotides in DNA that determines the sequence of amino acids in a protein. However, there can be variations in the genetic code due to mutations or specific adaptations in different species.
Mutations can occur in the genes that code for specific amino acids, leading to changes in the genetic code. For example, a single nucleotide substitution can result in a different amino acid being incorporated into a protein, which can have significant effects on its structure and function.
Another example of genetic code variation is seen in the mitochondria. The mitochondria have their own DNA and genetic code, which differs slightly from the nuclear DNA. This can lead to differences in the amino acid sequences of the proteins encoded by mitochondrial DNA.
Genetic code variations can also result from specific adaptations in different species. For instance, certain organisms, such as bacteria and archaea, have variations in their genetic code that allow them to utilize different amino acids or stop codons. These variations enable these organisms to adapt to their unique environments and carry out specialized functions.
Understanding genetic code variations is crucial for studying and deciphering the complexities of the genetic code. It helps scientists gain insights into the diversity of life and provides a foundation for further research in genetics and molecular biology.
Codons and Amino Acids
The genetic code refers to the sequence of nucleotides in DNA, which determines the sequence of amino acids in a protein. Proteins are essential for the structure, function, and regulation of cells, and the genetic code is responsible for encoding the information needed to produce these proteins.
Genetic mutations can occur in the DNA sequence, resulting in changes to the codons, which can in turn change the amino acid sequence of the protein. This can have significant effects on protein structure and function, and can lead to a variety of genetic disorders and diseases.
Codons are three-nucleotide sequences that correspond to specific amino acids or signaling sequences. There are a total of 64 possible codons, consisting of 4 different nucleotides (adenine, cytosine, guanine, and thymine) arranged in triplets. Each codon encodes either an amino acid or a stop signal.
For example, the codon “GCU” encodes the amino acid alanine, while the codon “UAA” is a stop signal, indicating the end of the protein sequence.
Amino Acids
Amino acids are the building blocks of proteins, and there are 20 different amino acids commonly found in proteins. Each amino acid is encoded by one or more codons. Some amino acids have multiple codons that encode them, while others have only one. For example, the amino acid alanine is encoded by the codons GCU, GCC, GCA, and GCG.
The genetic code is degenerate, meaning that multiple codons can encode the same amino acid. This redundancy allows for flexibility and robustness in the genetic code, as mutations that change a single nucleotide in a codon may not lead to a change in the corresponding amino acid.
Understanding the relationship between codons and amino acids is crucial for deciphering the genetic code and studying genetic disorders caused by mutations in the DNA sequence. By studying and manipulating the genetic code, scientists can gain insights into the complex mechanisms of protein synthesis and gene regulation.
Genetic Code Chart
The genetic code is the set of rules by which information encoded within DNA is converted into the sequence of amino acids in a protein. This process involves the translation of the nucleotide sequence in DNA into a specific sequence of amino acids.
Each set of three nucleotides in DNA, called a codon, corresponds to a specific amino acid. There are 64 possible codons, but only 20 different amino acids, so some amino acids are represented by multiple codons. For example, the codons GCA, GCC, GCG, and GCU all code for the amino acid alanine.
This genetic code chart shows the correspondence between codons and their corresponding amino acids:
Understanding the genetic code is crucial for studying and manipulating DNA. Mutations in the genetic code can lead to changes in the corresponding protein’s amino acid sequence, which can have significant effects on an organism’s traits and functions.
By deciphering the genetic code, scientists have been able to understand how variations in DNA sequences can result in different traits and diseases. This knowledge has opened up avenues for genetic engineering, gene therapy, and personalized medicine.
Overall, the genetic code is a fundamental concept in genetics and plays a crucial role in our understanding of how DNA encodes the information needed to build and maintain living organisms.
Genetic Code Evolution
The genetic code is the system of rules that dictates how the information stored in a genetic sequence is translated into a protein. It is made up of specific combinations of nucleotides that correspond to specific amino acids, which are the building blocks of proteins. The genetic code is universal, meaning that it is the same for all living organisms, with a few rare exceptions.
However, the genetic code has not always been the same throughout evolutionary history. It is believed that the code has evolved over time through a process called mutation. Mutations are changes that occur in the sequence of nucleotides in the DNA, and they can result in changes to the amino acid sequence that is produced during protein synthesis.
For example, a mutation in a specific nucleotide sequence can change the corresponding amino acid from one to another. This change can have a profound impact on the structure and function of the protein that is produced. Over time, these changes can accumulate and lead to the evolution of new protein functions.
Scientists have been studying the evolution of the genetic code to better understand its origins and how it has shaped life on Earth. By comparing the genetic codes of different organisms, they have discovered that certain amino acids are encoded by multiple codons, while others are encoded by only one or a few codons. This suggests that the genetic code has undergone a process of optimization and refinement throughout evolution.
Overall, the evolution of the genetic code is a fascinating area of research that provides valuable insights into the origins and diversity of life. By understanding how the code has evolved, scientists can gain a deeper understanding of the fundamental principles that govern life’s genetic processes.
Genetic Engineering
Genetic engineering is a field of study that involves manipulating the genetic material, or DNA, of an organism. This can be done by inserting, deleting, or modifying specific nucleotide sequences, leading to changes in the genetic code.
One common application of genetic engineering is the production of genetically modified organisms (GMOs). GMOs are created by introducing specific genes from one organism into the DNA of another, resulting in the expression of new traits. For example, scientists have engineered crops to be resistant to pests or diseases, improving crop yields and reducing the need for pesticides.
Understanding DNA and Genetic Code
DNA, or deoxyribonucleic acid, is a molecule that carries the genetic instructions for the development and functioning of all living organisms. It is made up of sequences of nucleotides, which are the building blocks of DNA.
The genetic code is the set of rules by which the information in DNA is translated into proteins. Proteins are made up of amino acids, and the specific sequence of amino acids determines the structure and function of the protein.
Mutations and Genetic Engineering
Genetic engineering can also involve introducing specific mutations into an organism’s DNA. A mutation is a change in the DNA sequence, which can result in altered protein production or function.
For example, by introducing a specific mutation into a gene that codes for a protein involved in cancer development, scientists can study the effects of the mutation on the protein’s function and potentially develop new treatments for cancer.
In conclusion, genetic engineering plays a crucial role in various fields, from agriculture to medicine. By manipulating the genetic code, scientists can create new organisms with desired traits and develop innovative solutions to address various challenges.
Applications of the Genetic Code
The genetic code, consisting of a sequence of nucleotides in DNA, holds the instructions for building proteins. This code is composed of codons, which are sets of three nucleotides that correspond to specific amino acids. Understanding the genetic code has many important applications in the field of genetics and biology.
One important application of the genetic code is in determining the amino acid sequence of a protein based on its DNA sequence. By analyzing the codons in a DNA sequence, scientists can determine the specific amino acids that make up a protein. This information is crucial for understanding the structure and function of proteins, which play a role in almost every biological process in living organisms.
Another application of the genetic code is in studying mutations. Mutations occur when there are changes in the DNA sequence, leading to changes in the amino acid sequence of a protein. Understanding how mutations affect the genetic code can help scientists understand the causes and effects of genetic diseases. For example, a mutation that results in the substitution of one amino acid for another can lead to the production of a non-functional protein, which can cause diseases like cystic fibrosis or sickle cell anemia.
The genetic code also has applications in genetic engineering and biotechnology. Scientists can use the code to design and synthesize DNA sequences that code for specific proteins. This has led to the development of genetically modified organisms (GMOs) that have beneficial traits, such as crops that are resistant to pests or diseases. The genetic code is also used in the production of therapeutic proteins, such as insulin, that are used to treat medical conditions.
Genomics is a branch of genetic science that focuses on the study of the entire genetic sequence of an organism, known as its genome. The genome is made up of DNA, which contains the instructions for building and maintaining an organism.
By analyzing the genetic sequence of an organism, researchers can gain insights into how genes function, how they are regulated, and how different genetic mutations may contribute to the development of diseases. Genomics encompasses a wide range of disciplines, including genetics, molecular biology, bioinformatics, and computational biology.
One of the fundamental areas of genomics is the understanding of the genetic code. The genetic code is the set of rules that determines how the sequence of nucleotides in DNA is translated into the sequence of amino acids in a protein. This code is universal, meaning that it is the same in all living organisms.
For example, the DNA sequence “ATG” codes for the amino acid methionine in all organisms. Mutations in the genetic code can lead to changes in the amino acid sequence of proteins, which can have profound effects on an organism’s traits and health.
Genomics plays a crucial role in medicine, as it helps researchers and healthcare professionals understand the genetic basis of diseases. By studying the genomes of individuals with certain diseases, scientists can identify potential targets for drug development and personalized treatment approaches. Genomics also has applications in agriculture, where it can be used to improve crop yield and develop genetically modified organisms.
Personalized Medicine
Personalized medicine is an emerging field that aims to provide tailored medical treatments based on an individual’s unique genetic makeup. By analyzing a person’s genetic code, scientists can gain insights into their susceptibility to certain diseases and their response to different medications.
At the core of personalized medicine is understanding the genetic code. DNA, the genetic material in our cells, contains the instructions for building proteins. Proteins are essential molecules that perform various functions in our body, and they are made up of chains of amino acids.
The genetic code is the set of rules that connects the sequence of nucleotides in DNA to the sequence of amino acids in a protein. Each group of three nucleotides, called a codon, corresponds to a specific amino acid or a stop signal. The order of codons in DNA determines the order of amino acids in a protein, which, in turn, determines the structure and function of the protein.
However, mutations can occur in the genetic code, altering the sequence of nucleotides and potentially changing the amino acids in a protein. These mutations can have a significant impact on protein function and can lead to the development of genetic disorders or increased susceptibility to certain diseases.
Benefits of Personalized Medicine
Personalized medicine has the potential to revolutionize healthcare by enabling targeted therapies and interventions. By understanding an individual’s unique genetic makeup, doctors can prescribe medications and treatments that are more likely to be effective and have fewer side effects.
Additionally, personalized medicine can aid in the early detection of diseases. By analyzing a person’s genetic code, scientists can identify genetic markers that indicate an increased risk for certain conditions. This allows for proactive measures such as lifestyle changes, increased monitoring, or preventive interventions to reduce the likelihood of developing the disease.
Challenges and Future Directions
While personalized medicine holds great promise, there are challenges that need to be addressed. One of the main challenges is the interpretation of genetic data. Analyzing the vast amounts of genetic information requires sophisticated algorithms and computational tools to identify relevant variations and their implications.
Privacy and ethical concerns also need to be carefully considered when implementing personalized medicine. The use of genetic information raises questions about data protection, consent, and potential discrimination based on genetic predispositions.
Despite these challenges, personalized medicine represents a new era in healthcare that has the potential to improve patient outcomes and revolutionize medical practices.
Ethical Considerations
Understanding the genetic code and how it translates into protein production is a fascinating area of study. However, this knowledge also raises important ethical considerations.
One ethical consideration is the potential for misuse of genetic information. The genetic code contains the instructions for building proteins, which are essential for the functioning of all living organisms. With this information, it is possible to manipulate the genetic sequence and, consequently, the proteins produced. This opens up the possibility of using genetic engineering to create new proteins or modify existing ones. These advances can have many potential benefits, such as developing new medicines or improving crop yields. However, they also raise concerns about the unintended consequences of altering the genetic code, as well as the potential for genetic discrimination or other forms of misuse.
Future Perspectives
In the future, understanding the genetic code and its complex relationship with the phenotypic traits of organisms will be crucial for advancements in various fields, such as medicine, agriculture, and biotechnology.
By unraveling the intricate mechanisms of the genetic code, scientists can gain valuable insights into the functioning of genes and their role in health and disease. This knowledge can pave the way for personalized medicine, where treatments are tailored to an individual’s genetic makeup.
In agriculture, understanding the genetic code can help develop crops with improved qualities, such as increased yield, drought resistance, or enhanced nutritional content. This can contribute to global food security and sustainable farming practices.
Biotechnology also stands to benefit from a deeper understanding of the genetic code. By modifying the code, scientists can create novel proteins with unique properties or optimize existing ones for specific applications. This has implications for the development of new drugs, enzymes, and biomaterials.
The genetic code is not static but subject to mutations, which are changes in the sequence of nucleotides. Understanding how these mutations affect the genetic code and ultimately the protein synthesis can shed light on the causes of genetic diseases and provide potential avenues for treatment.
Further research is needed to uncover the complexities of the genetic code and how it influences the diverse phenotypic traits observed in organisms. With advancements in sequencing technologies and computational analysis, scientists are poised to make significant breakthroughs in decoding the genetic information that governs life on Earth.
What is the genetic code?
The genetic code is the set of rules by which information encoded within genetic material (DNA or RNA sequences) is translated into proteins by living cells.
How does the genetic code work?
The genetic code works by using codons, which are three-letter sequences of nucleotides, to specify the amino acids that should be included in a protein. Each codon corresponds to a specific amino acid.
Can you give an example of how the genetic code is translated into proteins?
Sure! Let’s take the codon “AUG” as an example. This codon codes for the amino acid methionine. So, if a DNA or RNA sequence contains the codon “AUG”, it will result in the incorporation of a methionine amino acid into the growing protein chain.
What happens if there is a mistake in the genetic code?
If there is a mistake in the genetic code, it can lead to genetic disorders or diseases. Even a small error, such as a substitution of one nucleotide in a codon, can result in a non-functional protein or the wrong protein being produced.
Is the genetic code the same in all living organisms?
The genetic code is nearly universal, meaning it is almost the same in all living organisms. While there are a few exceptions and variations, the vast majority of genetic codes across different species are very similar.
The genetic code is the set of rules by which information encoded in genetic material (DNA or RNA sequences) is translated into proteins (amino acid sequences)
How is the genetic code read?
The genetic code is read in groups of three nucleotides called codons. Each codon corresponds to a specific amino acid or a stop signal.
What is the start codon?
The start codon is a specific codon (AUG) that signals the beginning of protein synthesis.
Can a single amino acid be encoded by multiple codons?
Yes, a single amino acid can be encoded by multiple codons. For example, the amino acid leucine can be encoded by six different codons (UUA, UUG, CUU, CUC, CUA, CUG).
What happens if there is a mutation in the genetic code?
If there is a mutation in the genetic code, it can lead to changes in the amino acid sequence of a protein, which can have various effects on its function.
Related posts:
- Unraveling the Mystery – The Fascinating Reason Why Genetic Code is Degenerate
- Mastering the Art of Utilizing the Genetic Code Table – A Comprehensive Guide for Beginners and Experts
- Investigating Alternatives – Exploring the Deep Secrets of Alternative Genetic Codes
- Genetic Code – The Fascinating Non-Overlapping Puzzle of DNA Sequences
- Genetic Code – The Unambiguous Blueprint of Life
- Why the genetic code is regarded as commaless
- Understanding the Characteristics of the Genetic Code – Unlocking the Secrets of Life
- Understanding the intricate and fascinating world of genetic code – Unraveling the mysteries of life
- Gene to a Protein – Understanding the Journey from DNA to Protein
- Decoding the Mystery – Exploring the Relationship Between Genes and Proteins
Genetic Code
- 1.0 What is a Genetic Code?
The concept of the genetic code was initially proposed by George Gamow, suggesting a fundamental relationship between nucleotide sequences and the amino acids they encode. The actual deciphering of the genetic code was achieved through the groundbreaking work of Marshall Nirenberg, Heinrich Matthaei, and Har Gobind Khorana. Their research illuminated how sequences of amino acids in proteins are determined by the sequences of nucleotides in DNA or its RNA transcript.
Proteins are composed of 20 different amino acids, each specified by the genetic information encoded in DNA. During transcription, the genetic instructions in DNA are transcribed to mRNA, transferring the information through complementary nitrogenous base pairing. Each amino acid is represented by a specific sequence of nucleotides on the mRNA, known as a codon. Thus, a codon is a triplet of nucleotides on mRNA that specifies a particular amino acid. The entirety of these codons, comprising the mRNA molecule, forms the genetic code, which encompasses all necessary information for polypeptide chain synthesis.
Triplet Codon
The central challenge in understanding the genetic code involved determining the precise number of nucleotides within a codon required to specify each of the 20 different amino acids. Messenger RNA (mRNA) is composed of four types of nitrogenous bases: adenine (A), uracil (U), guanine (G), and cytosine (C). The complexity arose in figuring out how combinations of these four bases could encode 20 distinct amino acids.
A singlet code, where each codon is composed of a single nitrogen base, would produce only four possible codons (A, U, G, C). This arrangement is inadequate because it allows for only four amino acids to be specified, far less than the 20 needed.
Calculation: 4 1 =4 codons
A doublet code, with codons made up of two nitrogen bases, increases the number of possible codons to 16 (by considering all possible base pairs).
Calculation: 4 2 =16 codons
However, 16 codons are still insufficient to represent all 20 amino acids.
Recognizing these limitations, George Gamow, in 1954, proposed the concept of a triplet code. In this model, each codon consists of three nitrogen bases, which significantly expands the coding capacity.
Triplet code calculation: 4 3 =64 codons
With 64 possible codons, this system is more than adequate to encode all 20 amino acids. This realization was pivotal in understanding the genetic code's structure, providing a sufficient number of codons to not only represent each amino acid but also include start and stop signals necessary for protein synthesis.
- 2.0 Genetic Code Table

3.0 Characteristics of Genetic Code
- Triplet Nature: A codon in genetics consists of three contiguous nitrogen bases on the mRNA, each specifying a single amino acid in a polypeptide chain. For example, an mRNA strand with 90 nitrogen bases would determine a polypeptide chain of 30 amino acids, as the 90 bases form 30 codons, each coding for one amino acid.
- Universality: The genetic code is nearly universal across all forms of life, from viruses and bacteria to unicellular and multicellular organisms. This universality suggests a common evolutionary origin for all life.
- Non-Ambiguity and Specificity: Each codon uniquely specifies only one amino acid, making the genetic code non-ambiguous. However, an exception exists with the GUG codon, which can code for both valine and, in some cases, methionine, highlighting a rare instance of ambiguity.
- Non-Overlapping: Each nitrogen base is part of only one codon, ensuring that codons do not overlap within the genetic sequence.

- Commaless: Codons are sequenced continuously without any punctuation between them. This arrangement means that adding or deleting a nucleotide can shift the reading frame, altering the amino acid sequence synthesized thereafter. For instance, a mutation in the middle of a sequence specifying 50 amino acids could result in the correct synthesis of the first 25 amino acids, but the remaining sequence would be altered.

- Degeneracy: With 64 possible codons and only 20 amino acids, most amino acids are encoded by more than one codon, a feature known as degeneracy of genetic code. This characteristic was discovered by Baurnfield and Nirenberg.
There are three amino acids encoded by six different codons: serine, leucine, arginine. Only two amino acids are specified by a single codon; one of these is the amino-acid methionine, specified by the codon AUG, which also specifies the start of translation; the other is tryptophan, specified by the codon UGG. The degeneracy of the genetic code is what accounts for the existence of silent mutations.
Degeneracy results because a triplet code designates 20 amino acids and a stop codon. Because there are four bases, triplet codons are required to produce at least 21 different codes. For example, if there were two bases per codon, then only 16 amino acids could be coded for (4²=16). Because at least 21 codes are required, then 4³ gives 64 possible codons, meaning that some degeneracy must exist.
- 4.0 Wobble Hypothesis
According to this hypothesis, the base in the first position of anticodon on tRNA is usually an abnormal base, like inosine, pseudouridine, tyrosine, etc. These abnormal bases are able to pair with more than one type of nitrogenous base in the third position of the codon on mRNA.
eg. Inosine (I) can pair with A, C, or U. This base is called a Wobble base or fluctuating base. Wobble occurs at position 1 of the anticodon and position 3 of the codon.
The wobble hypothesis states that the third position (3') of the codon on mRNA and the first position (5') of the anticodon on tRNA are bound less tightly than the other pair and therefore, offer unusual base combinations.
A single amino acid may be specified by many codons, i.e. called degeneracy. Degeneracy is due to the last base in a codon, which is known as a wobble base. Thus the first two codons are more important in determining the amino acid and the one differs without affecting the coding known as the Wobble hypothesis.
Thus according to this, in codon-anticodon pairing, the third base of the tRNA anticodon does not have to pair with a complementary codon. It is called a wobble base and this position is called the wobble position. The actual base pairing occurs in the first two positions only.

- 5.0 Types of Genetic Code
- Chain Initiation Codons
- Protein synthesis begins with the help of initiation codons, primarily AUG and, under certain conditions, GUG.
- In eukaryotes, the AUG codon codes for the amino acid methionine. In prokaryotes, AUG codes for a modified form of methionine, known as N-formylmethionine, which is used to start protein synthesis.
- Occasionally, the GUG codon can also act as a start codon. Although GUG normally codes for the amino acid valine, when positioned at the start of an mRNA sequence, it can code for methionine, indicating its role in initiating protein synthesis under specific circumstances.
- Chain Termination Codons
- The termination of polypeptide chain synthesis is signaled by three specific codons, known as stop or nonsense codons. These codons do not specify any amino acid and serve to halt the translation process. The three stop codons are:
- UAA (Ochre)
- UAG (Amber)
- These stop codons are essential for indicating the end of a protein-coding sequence, ensuring that the polypeptide chain is released from the ribosome at the correct point.
- Implications
- With three codons designated as stop codons, 61 of the total 64 codons are left as sense codons. These sense codons are responsible for specifying the 20 standard amino acids used in protein synthesis.
Table of Contents
- 1.1 Triplet Codon
- 3.0 Characteristics of Genetic Code
Frequently Asked Questions
How many codons are stop codons .
Three codons are stop codons. UAA, UAG, UAG
Which are starting codons in genetic codes?
AUG and GUG are starting codons.
AUG codes for ____ ?
How many codons code for leucine , join allen.
(Session 2025 - 26)
Rethink Biology Notes
Ace the biology exams with expert notes
Genetic Code Overview

- Definition : Genetic Code is the set of rules by which information encoded in genetic material (DNA or RNA sequences) is translated into proteins by living cells.
- Universal : Applies to almost all organisms, with few exceptions.
Table of Contents
Characteristics of Genetic Code
- Triplet Code : Each codon consists of three nucleotides.
- Non-overlapping : Each nucleotide is part of only one codon.
- Degenerate : Multiple codons can encode the same amino acid.
- Unambiguous : Each codon codes for only one amino acid.
- Start Codon : AUG is the initiation codon, coding for Methionine.
- Stop Codons : UAA, UAG, and UGA signal termination of translation.
Codon Usage
- Redundancy : Some amino acids are encoded by more than one codon.
- Wobble Hypothesis : Flexibility in the third base of the codon allows for multiple codons to pair with the same anticodon.
Translation Process
- Initiation : Ribosome assembles around the target mRNA. The start codon is recognized, and Met is established as the first amino acid.
- Elongation : tRNAs bring amino acids to the ribosome according to the sequence of codons in mRNA.
- Termination : When a stop codon is reached, the ribosome releases the polypeptide.
Genetic Code Exceptions
- Mitochondrial Variations : Slight differences in the genetic code found in mitochondria.
- Expanded Genetic Code : Some organisms can incorporate non-standard amino acids through codon reassignment or by using specific tRNA synthetases.
Clinical Significance
- Mutations : Changes in the genetic code can lead to diseases if they result in dysfunctional proteins.
- Genetic Diseases : Caused by mutations that disrupt the normal function of genes.
Applications in Biotechnology
- Protein Engineering : Designing proteins with new functions by manipulating the genetic code.
- Gene Therapy : Correcting defective genes responsible for disease development.
The genetic code is the universal language translating DNA and RNA sequences into proteins. Despite being highly conserved, it shows characteristics like redundancy and non-overlapping sequences. The translation process—initiation, elongation, and termination—is crucial for protein synthesis. Variations like mitochondrial differences and the expanded genetic code highlight its adaptability. Understanding the genetic code’s role in mutations and genetic diseases underscores its clinical importance, while its applications in biotechnology, such as protein engineering and gene therapy, reveal its potential for innovation.

Check out our Latest Posts
- Applications of Light Microscopy
- Applications of Atomic Force Microscopy
- Atomic Force Microscopy
- Transmission Electron Microscope (TEM)
- Scanning Electron Microscope (SEM)
- Why Does Water Expand When It Freezes
- Gold Foil Experiment
- Faraday Cage
- Oil Drop Experiment
- Magnetic Monopole
- Why Do Fireflies Light Up
- Types of Blood Cells With Their Structure, and Functions
- The Main Parts of a Plant With Their Functions
- Parts of a Flower With Their Structure and Functions
- Parts of a Leaf With Their Structure and Functions
- Why Does Ice Float on Water
- Why Does Oil Float on Water
- How Do Clouds Form
- What Causes Lightning
- How are Diamonds Made
- Types of Meteorites
- Types of Volcanoes
- Types of Rocks
Genetic Code
The genetic code is a set of rules or instructions that dictate how the information stored in DNA (deoxyribonucleic acid) is translated into functional proteins within living cells.
It is a triplet code, which means it operates in groups of three nucleotide bases, known as codons. Each codon corresponds to a specific amino acid or a termination signal for protein synthesis .
How does a Cell Interpret the Genetic Code
The journey of information transfer within the genetic code is a two-step process: transcription and translation .
- Transcription : The information in DNA is copied into an mRNA by the enzyme RNA polymerase .
- Translation : It is the process of converting an mRNA into proteins. Here the mRNA is read in groups of three, known as codons, that specify a particular amino acid or a stop signal. tRNA molecules bring the corresponding amino acids specific to each codon, allowing them to link together in a particular sequence. This chain of amino acids then folds into a functional protein.
The genetic code is the complete set of messages between codons and amino acids (or stop signals). Thus, the primary purpose of genetic code is to direct the synthesis of proteins based on the information in the DNA molecule .
How was the Genetic Code Deciphered
- From 1953 to 1956, Francis Crick and James Watson worked on the double-helix structure. They hypothesized that information from DNA is transmitted to proteins.
- In the mid-1950s, George Gamow deduced the genetic code to be composed of triplets of nucleotides. He was the first to propose that a group of three successive nucleotides in a gene may code for one amino acid in a polypeptide.
- Around 1961, the concept of codons was first described by Francis Crick and his colleagues. During the same year, Marshall Nirenberg and Heinrich Matthaei start deciphering the genetic code. They showed that the RNA sequence UUU specifically coded for the amino acid phenylalanine.
- Following the start of the discovery of the genetic code, Nirenberg, Philip Leder, and Gobind Khorana completed the rest of the genetic code and described all the three-letter codons for the corresponding amino acids.
Characteristics of the Genetic Code
1. triplet code (codon).
As we know, a sequence of three nucleotides codes for a particular amino acid. Thus, the genetic code is a triplet. The four bases of nucleotide: adenine (A), guanine (G), thymine (T), and cytosine (C) make up all the 64 codons, including 61 coding for specific amino acids and three stop codons (UAA, UAG, and UGA). These determine the genetic code.
2. Universality
The genetic code remains the same for all living organisms, whether a bacterium, plant , or animal.
3. Non-Ambiguity
While multiple codons code some amino acids, each codon always specifies a single amino acid. Thus, the genetic code is unambiguous, ensuring that the instructions encoded in the code are clear and precise. The precise one-to-one correspondence between codons and amino acids is essential for accurately synthesizing proteins that carry out various biological functions.
4. Redundancy and Degeneracy (One Amino Acid, Many Codons)
The genetic code employs a degree of redundancy, where multiple codons can code for the same amino acid. All four codons, CCU, CCC, CCA, and CCG, encode the amino acid proline. It is crucial because it minimizes the harmful effects of incorrectly placed nucleotides on protein synthesis.
This redundancy is not arbitrary; it results from the ‘wobble’ phenomenon—a property in which the third nucleotide of a codon (the ‘wobble position’) can be flexible in its base pairing. It allows a single tRNA molecule to recognize and bind to multiple codons, enhancing the efficiency of protein synthesis. The wobble property also provides a buffer against errors during transcription and translation, contributing to the accuracy of protein synthesis.
5. Polarity
Each triplet is read from the 5’ → 3’ direction. The first base is always 5’, followed by a base in the middle, and then a 3’ base. Thus, the codons have a fixed polarity.
6. Start and Stop Codons
Within the genetic code, there are specific codons that act as ‘start’ and ‘stop’ signals for protein synthesis. The start codon, AUG, codes for the amino acid methionine and marks the beginning of protein synthesis.
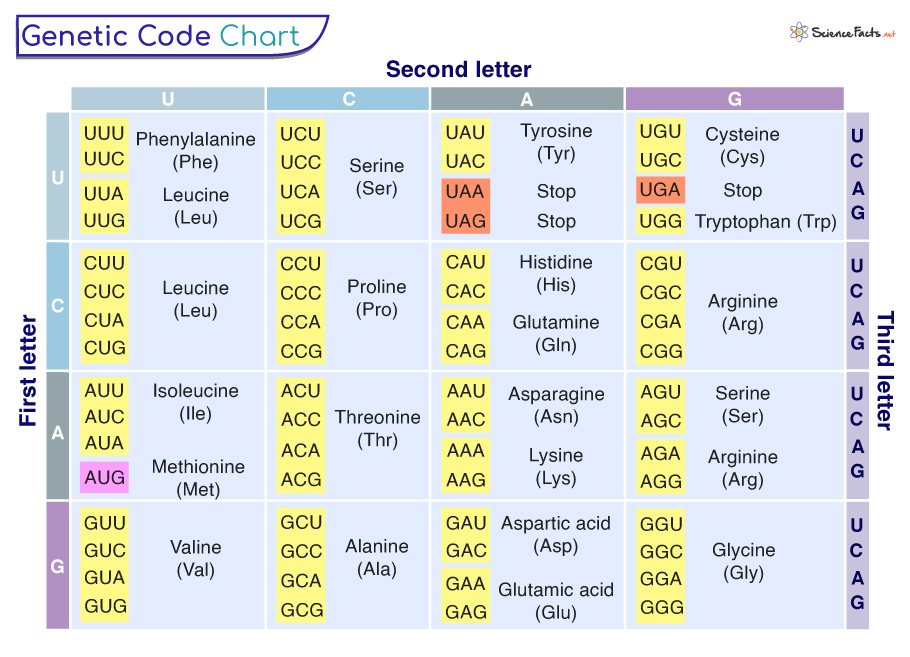
Stop codons (UAA, UAG, and UGA) signal the termination of protein synthesis, ensuring the protein is released from the ribosome in its complete form. These signals play an essential role in regulating the initiation and termination of protein synthesis.
As messenger RNA (mRNA) directs protein synthesis when ribosomes synthesize proteins, the standard genetic code is originally represented as an RNA codon table organized in a wheel.
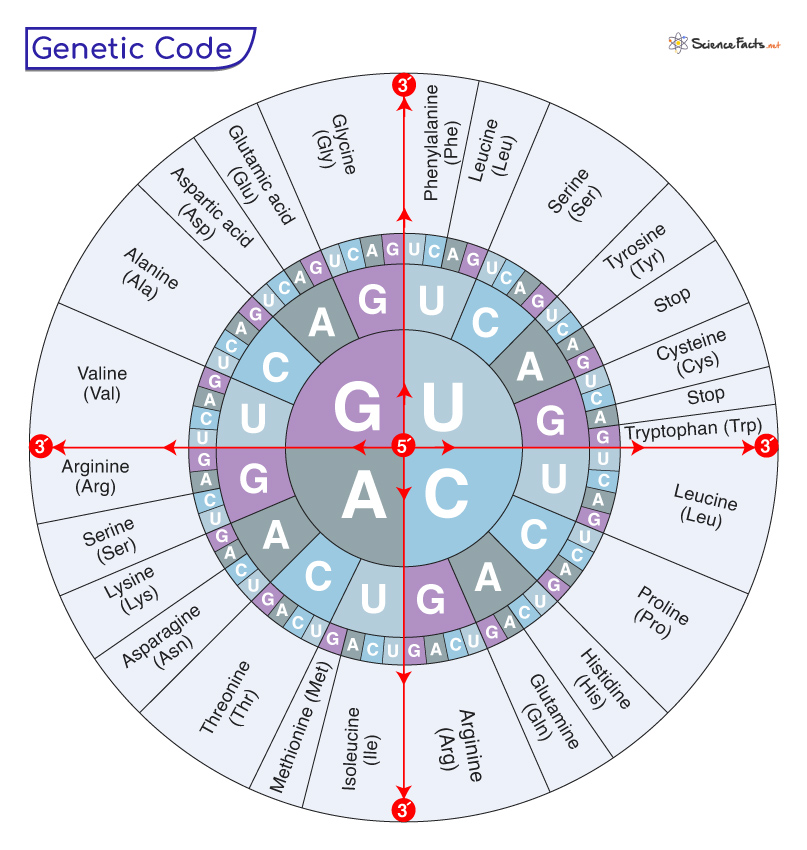
7. Reading Frame
The start codon is always crucial because it determines where the translation will begin on the mRNA. It also determines the reading frame, which codes for the subsequent amino acids.
The same sequence of nucleotides can encode different polypeptides depending on the position of the start codon and, therefore, the frame in which the codons are read.
Alternative Genetic Code
The genetic code is universal, with codons coding for a fixed number of amino acids and similar START and STOP signals in the genes. However, there are some exceptions to this rule.
- Attributing one or two of the STOP codons to an amino acid
- Both GUG and AUG can function as start codons, although GUG codes for valine
- The genetic code in mitochondria differs from the standard genetic code used in the cell nucleus
- Genetic code – Genome.gov
- The Genetic Code – Khanacademy.org
- Genetic code – Nature.com
- Understanding the Genetic Code – Ncbi.nlm.nih.gov
- Deciphering the Genetic Code – Acs.org
Article was last reviewed on Wednesday, September 13, 2023
Related articles
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Popular Articles
Join our Newsletter
Fill your E-mail Address
Related Worksheets
- Privacy Policy
© 2024 ( Science Facts ). All rights reserved. Reproduction in whole or in part without permission is prohibited.
- General Chemistry
- Organic Chemistry
- Analytical Chemistry
- GOB Chemistry
- Biochemistry
- Intro to Chemistry
- General Biology
- Microbiology
- Anatomy & Physiology
- Cell Biology
- College Algebra
- Trigonometry
- Precalculus
- Business Calculus
- Microeconomics
- Macroeconomics
- Financial Accounting
Social Sciences
Programming.
- Introduction to Python
- Microsoft Power BI
- Data Analysis - Excel
- Introduction to Blockchain
- HTML, CSS & Layout
- Introduction to JavaScript
- R Programming
Product & Marketing
- Agile & Product Management
- Digital Marketing
- Project Management
- AI in Marketing
Improve your experience by picking them
- History of Genetics 16m
- Modern Genetics 12m
- Fundamentals of Genetics 22m
- Mendel's Experiments and Laws 17m
- Inheritance in Diploids and Haploids 33m
- Monohybrid Cross 32m
- Dihybrid Cross 58m
- Sex-Linked Genes 21m
- Probability and Genetics 20m
- Pedigrees 31m
- Understanding Independent Assortment 11m
- Chi Square Analysis 34m
- Sex Chromosome 20m
- X-Inactivation 11m
- Overview of interacting Genes 11m
- Pleiotropy 6m
- Epistasis and Complementation 37m
- Variations of Dominance 9m
- Penetrance and Expressivity 4m
- Organelle DNA 9m
- Maternal Effect 5m
- Mapping Overview 11m
- Crossing Over and Recombinants 39m
- Mapping Genes 19m
- Trihybrid Cross 34m
- Multiple Cross Overs and Interference 9m
- Chi Square and Linkage 22m
- Mapping with Markers 9m
- Positional Cloning 3m
- Working with Microorganisms 13m
- Bacterial Conjugation 28m
- Bacterial Transformation 10m
- Bacteriophage Genetics 18m
- Transduction 10m
- Chromosomal Mutations: Aberrant Euploidy 20m
- Chromosomal Mutations: Aneuploidy 13m
- Chromosomal Rearrangements: Overview 8m
- Chromosomal Rearrangements: Deletions 7m
- Chromosomal Rearrangements: Duplications 7m
- Chromosomal Rearrangements: Inversions 9m
- Chromosomal Rearrangements: Translocations 41m
- DNA as the Genetic Material 13m
- DNA Structure 10m
- Alternative DNA Forms 3m
- Bacterial and Viral Chromosome Structure 4m
- Eukaryotic Chromosome Structure 14m
- Semiconservative Replication 17m
- Overview of DNA Replication 25m
- Telomeres and Telomerase 11m
- Recombination 16m
- Mitosis 22m
- Meiosis 31m
- Development of Animal Gametes 25m
- Development of Plant Gametes 14m
- Overview of Transcription 9m
- Transcription in Prokaryotes 13m
- Transcription in Eukaryotes 13m
- RNA Modification and Processing 12m
- RNA Interference 10m
- The Genetic Code 15m
- Transfer RNA 4m
- Ribosomal Structure 7m
- Translation 21m
- Proteins 9m
- Lac Operon 23m
- Tryptophan Operon and Attenuation 21m
- Lambda Bacteriophage and Life Cycle Regulation 23m
- Arabinose Operon 5m
- Riboswitches 6m
- Overview of Eukaryotic Gene Regulation 13m
- GAL Regulation 7m
- Epigenetics, Chromatin Modifications, and Regulation 15m
- Post Translational Modifications 7m
- Studying the Genetics of Development 12m
- Developmental Patterning Genes 20m
- Early Developmental Steps 11m
- Overview of Genomics 4m
- Sequencing the Genome 35m
- Genomic Variation 12m
- Bioinformatics 10m
- Comparative Genomics 8m
- Genomics and Human Medicine 19m
- Functional Genomics 11m
- Proteomics 8m
- Discovery of Transposable Elements 9m
- Transposable Elements in Prokaryotes 9m
- Transposable Elements in Eukaryotes 19m
- Regulation of Transposable Elements 8m
- Types of Mutations 28m
- Spontaneous Mutations 12m
- Induced Mutations 8m
- DNA Repair 17m
- Genetic Cloning 9m
- Methods for Analyzing DNA 9m
- Overview of Cancer 21m
- Cancer Mutations 7m
- Mathematical Measurements 15m
- Traits and Variance 18m
- Analyzing Trait Variance 11m
- Heritability 20m
- QTL Mapping 20m
- Hardy Weinberg 19m
- Allelic Frequency Changes 31m
- Overview of Evolution 10m
- Speciation 8m
- Phylogenetic Trees 10m
Write a short essay that summarizes the key properties of the genetic code and the process by which RNA is transcribed on a DNA template.

IMAGES
COMMENTS
Essay # 1. Concept of Genetic Code: Amino acid sequences of the protein are governed by the nucleotide sequences of the mRNA. This specific relationship between the nucleotide sequence and amino acid sequence is known as genetic code, which was deciphered by Marshall Nirenberg and his colleagues in early 1960s.
Apr 2, 2017 · After this "cracking" of the genetic code, several properties of the genetic code became apparent: The genetic code is composed of nucleotide triplets. In other words, three nucleotides in mRNA (a codon) specify one amino acid in a protein. The code is non-overlapping. This means that successive triplets are read in order. Each nucleotide is ...
Mar 16, 2024 · Understanding the universal genetic code also has implications for medicine. For example, genetic diseases are often caused by mutations in the DNA that disrupt the normal reading of the genetic code. By studying the universal genetic code, researchers can better understand the molecular basis of genetic diseases and develop new treatments.
The genetic code consists of four nitrogenous bases that form two base pairs. These four nitrogenous bases store all the vital information necessary to generate life. The investigators in the experiment aimed to build upon the existing genetic code. The investigators synthesized unnatural base pairs (UBPs) to incorporate into the DNA of E. coli ...
The three-letter "words" of the genetic code are known as codons. This experimental approach was also used to work out the relationship between individual codons and the various amino acids. After this "cracking" of the genetic code, several properties of the genetic code became apparent: * The genetic code is composed of nucleotide triplets.
Dec 20, 2023 · Overall, the genetic code is a fundamental concept in genetics and plays a crucial role in our understanding of how DNA encodes the information needed to build and maintain living organisms. Genetic Code Evolution. The genetic code is the system of rules that dictates how the information stored in a genetic sequence is translated into a protein.
3.0 Characteristics of Genetic Code Triplet Nature: A codon in genetics consists of three contiguous nitrogen bases on the mRNA, each specifying a single amino acid in a polypeptide chain. For example, an mRNA strand with 90 nitrogen bases would determine a polypeptide chain of 30 amino acids, as the 90 bases form 30 codons, each coding for one ...
Genetic Diseases: Caused by mutations that disrupt the normal function of genes. Applications in Biotechnology. Protein Engineering: Designing proteins with new functions by manipulating the genetic code. Gene Therapy: Correcting defective genes responsible for disease development. Conclusion. The genetic code is the universal language ...
Sep 13, 2023 · 1. Triplet Code (Codon) As we know, a sequence of three nucleotides codes for a particular amino acid. Thus, the genetic code is a triplet. The four bases of nucleotide: adenine (A), guanine (G), thymine (T), and cytosine (C) make up all the 64 codons, including 61 coding for specific amino acids and three stop codons (UAA, UAG, and UGA).
Write a short essay that summarizes the key properties of the genetic code and the process by which RNA is transcribed on a DNA template.